
Introduction
In today’s rapidly evolving technological landscape, the role of a Site Reliability Engineer (SRE) has emerged as a crucial bridge between development and operations. Combining coding expertise with operational know-how, SREs play a pivotal role in ensuring complex systems’ reliability, scalability, and performance.
This comprehensive guide dives deep into the exciting career path of a Site Reliability Engineer, shedding light on key responsibilities, required skills, growth opportunities, and the steps aspiring professionals can take to embark on this rewarding journey.

- Role of a Site Reliability Engineer Role
- Responsibilities of a Site Reliability Engineer
- Education and Career Preparation for Aspiring Site Reliability Engineer
- Industry Spotlight: Real-World Applications: Unveiling the Power of SRE in Action
- Growth and Advancement: Soaring to New Heights in the Site Reliability Engineer Universe
- A Day in the Life of a Site Reliability Engineer: Navigating Challenges with Tech Prowess
- Conclusion
- FAQs
Role of a Site Reliability Engineer Role
- Tech Architects Beyond Compare: Site Reliability Engineers (SREs) are the unsung heroes of the digital realm, blending the art of coding with the science of operations to create robust, reliable, and high-performing systems.
- Bridge Builders: Imagine a world where developers and operations teams communicate seamlessly, where software is as dependable as it is innovative. SREs serve as the bridge that connects these two worlds, orchestrating a harmonious symphony of tech brilliance.
- The Dual Persona: SREs wear multiple hats – they code like software engineers and manage infrastructure like operations experts. This duality is their secret sauce, allowing them to anticipate issues before they arise and engineer solutions that stand up to the test of scalability.
- Guardians of User Experience: SREs aren’t just behind-the-scenes tech wizards; they’re the guardians of user experiences. They ensure that your favorite apps load quickly, your online transactions remain secure, and your binge-watching marathons are uninterrupted by downtime.
- Operational Efficiency Virtuosos: Efficiency isn’t just a buzzword; it’s an SRE mantra. These professionals automate routine tasks, analyze system performance, and optimize infrastructure to ensure that systems function efficiently, even when faced with surging demands.
- Learning from Incidents: SREs are detectives of the digital realm. When an incident occurs, they don their investigative hats, diving deep into the problem to dissect its root causes. This post-mortem approach drives continuous improvement, ensuring that history doesn’t repeat itself.
- Engineering Trust: Reliability isn’t just about keeping systems running; it’s about fostering trust. SREs engineer mechanisms that guarantee uptime, create redundancy, and implement graceful degradation, all to deliver consistent, trustworthy user experiences.
- Adapting to Change: In a tech landscape where change is the only constant, SREs are adaptable chameleons. They anticipate shifts, adapt to evolving technologies, and ensure systems remain agile and ready to embrace the future.
External Link Suggestion: https://landing.google.com/sre/
Responsibilities of a Site Reliability Engineer
- System Health Guardians: SREs are the vigilant watchers of system health, monitoring performance metrics and proactively addressing any signs of distress. They ensure that systems run like well-oiled machines, delivering top-notch experiences to users.
- Incident Responders: When systems hiccup or falter, SREs are the first responders on the scene. They’re the digital firefighters who swiftly diagnose issues, troubleshoot bottlenecks, and restore normalcy, minimizing downtime and keeping disruptions at bay.
- Automation Architects: Repetitive tasks beware – SREs wield the power of automation. They craft scripts, tools, and workflows that automate routine processes, freeing up time for innovation and strategic thinking.
- Infrastructure Wizards: SREs build the foundation upon which digital worlds are erected. They design, develop, and maintain infrastructure, creating environments that can scale effortlessly, handle traffic spikes, and gracefully adapt to changing demands.
- Scalability Sorcerers: Scaling isn’t just about adding more servers; it’s a delicate dance of optimizing resources. SREs are the maestros who orchestrate this dance, ensuring that systems expand and contract with seamless grace, no matter the load.
- Champions of Reliability Engineering: As the name suggests, SREs engineer reliability into the very fabric of systems. They predict potential failures, engineer redundancy, and design mechanisms for graceful degradation – all in the pursuit of unwavering reliability.
- Performance Analysts: SREs don’t just glance at metrics; they interpret them like seasoned data wizards. They identify patterns, detect anomalies, and use data-driven insights to fine-tune systems for optimal performance.
- Continuous Improvement Evangelists: Learning from incidents is an SRE superpower. They conduct post-mortems, analyze failures, and use these insights to drive continuous improvement, ensuring that systems evolve to become stronger and more resilient.
- Collaborative Commanders: SREs are the bridge between development and operations teams. They collaborate, communicate, and ensure that the goals of both sides are met, harmonizing the entire tech ecosystem for maximum efficiency.
- Security Sentinels: Security isn’t an afterthought; it’s a core responsibility. SREs implement security best practices, safeguarding systems against vulnerabilities, and working diligently to protect user data and maintain privacy.
Education and Career Preparation for Aspiring Site Reliability Engineer
- Diverse Educational Pathways: There are various educational pathways for individuals interested in pursuing degrees in computer science, software engineering, or related fields. The tech industry welcomes professionals from diverse educational backgrounds who possess the right skills and passion.
- Certification Champions: Certifications can be your golden ticket. Consider certifications like “Google Cloud Professional DevOps Engineer” or “AWS Certified DevOps Engineer” to validate your expertise and stand out in a competitive landscape.
- Hands-On Learning: Theory is crucial, but hands-on experience is the catalyst for growth. Seek internships, co-op programs, or entry-level positions to immerse yourself in the practical world of SRE, learning from real-world challenges and triumphs.
- Coding Craftsmanship: Becoming an SRE is like weaving code poetry. Hone your programming skills in languages like Python, Go, or Java. A solid grasp of coding not only empowers you to automate tasks but also positions you as a tech maven.
- System Savviness: An SRE needs to know the systems inside out. Study system architecture, networking, and the intricacies of different operating systems. This knowledge helps you troubleshoot, optimize, and build robust infrastructures.
- Troubleshooting Tenacity: An SRE is a Sherlock of tech – a relentless problem solver. Cultivate your troubleshooting skills. Learn to dissect complex issues, trace their origins, and devise innovative solutions that leave no stone unturned.
- Collaboration and Communication: SREs don’t work in isolation. They’re part of a dynamic tech ecosystem. Cultivate collaboration and communication skills to liaise effectively with developers, operations teams, and stakeholders.
- Continuous Learning Ethos: The tech universe never stops evolving, and neither should you. Stay updated with the latest trends, tools, and methodologies. Engage in online courses, attend workshops, and devour tech literature voraciously.
- Personal Projects that Shine: Create a portfolio that gleams with personal projects. Develop tools, automate processes, or contribute to open-source projects. Your portfolio showcases your passion, skills, and real-world impact.
- Problem-Solving Showcase: Technical interviews are part of the SRE journey. Sharpen your problem-solving abilities through coding challenges, algorithm practice, and mock interviews. Showcase your analytical prowess with confidence.
Industry Spotlight: Real-World Applications: Unveiling the Power of SRE in Action
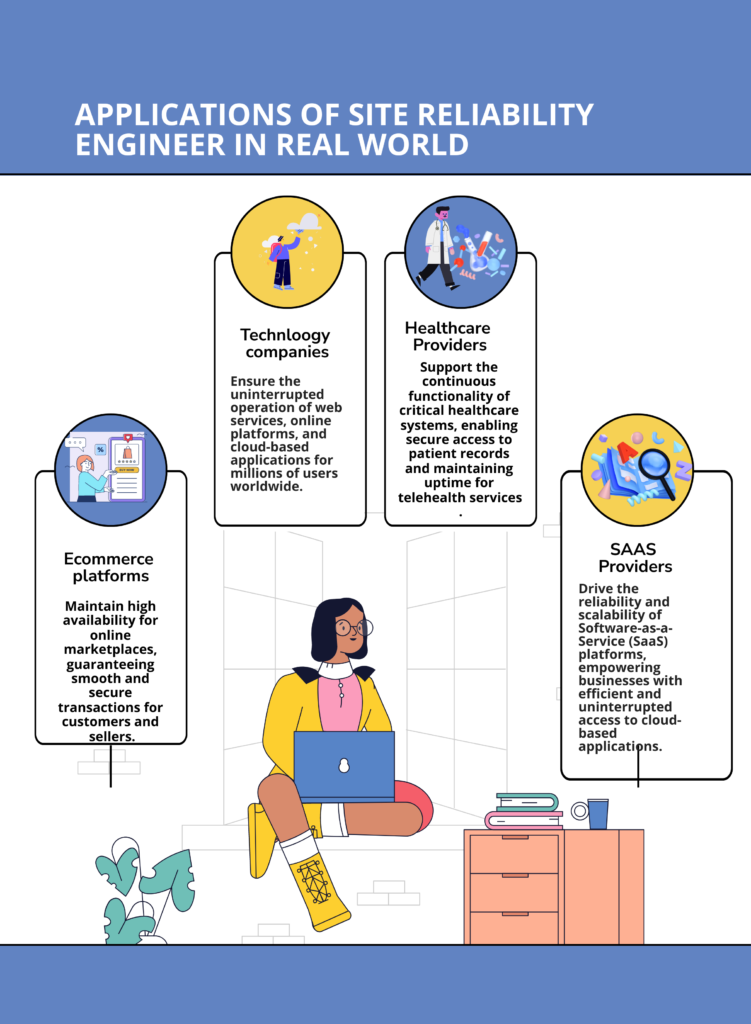
In the dynamic landscapes of e-commerce, cloud services, finance, and beyond, Site Reliability Engineers (SREs) are the unsung heroes behind seamless digital experiences. Let’s dive into how SREs wield their magic in various industries.
E-Commerce Excellence: In the bustling realm of e-commerce, SREs ensure that your online shopping spree doesn’t end in frustration. They optimize platforms to handle sudden surges in traffic during sales, ensuring smooth transactions and minimizing cart abandonment. Their behind-the-scenes efforts translate to front-end satisfaction, making shopping a breeze.
Cloud Service Brilliance: Cloud services underpin our digital existence, and SREs are the architects of their reliability. They optimize cloud infrastructure, enabling services to scale effortlessly based on demand. Whether it’s streaming your favorite show or accessing critical files, SREs ensure that the cloud remains a dependable ally.
Finance and Banking Security: In the world of finance and banking, where milliseconds matter, SREs hold the fort. They guarantee that online transactions are secure, swift, and uninterrupted. Their meticulous work ensures that your investments are executed flawlessly, and your financial data remains impervious to threats.
Healthcare Harmony: Even in the realm of healthcare, SREs play a crucial role. They ensure that medical systems, from electronic health records to telemedicine platforms, operate smoothly and securely. SREs’ efforts contribute to seamless patient care, enabling healthcare professionals to focus on what truly matters.
Gaming Galore: Online gaming isn’t all fun and games – it’s a complex digital ecosystem. SREs work tirelessly to optimize game servers, ensuring low latency and minimal downtime. When you’re immersed in a virtual world, SREs are the silent architects of your gaming universe.
Telecommunications Triumph: In the age of constant connectivity, telecom networks rely on SREs to keep conversations flowing. They ensure that voice calls, video chats, and data transfers remain uninterrupted, contributing to the global web of communication.
From shopping carts to cloud servers, from financial transactions to virtual battles, and beyond – SREs are the gears that keep these industries spinning. Their work impacts our daily lives, shaping the digital experiences we often take for granted.

Growth and Advancement: Soaring to New Heights in the Site Reliability Engineer Universe
In the exciting realm of Site Reliability Engineering (SRE), the journey doesn’t stop at maintaining systems. It’s a dynamic path that offers abundant opportunities for growth, specialization, and exploration.
Leadership Horizon: As an SRE, your journey can ascend to leadership roles. With your profound understanding of systems, you’re poised to guide teams, mentor junior engineers, and shape the strategic direction of projects. From SRE Manager to Director, leadership roles beckon those with a passion for both technology and people.
Specialization Avenue: SREs can choose to become specialists, diving deep into areas like security, performance optimization, or cloud architecture. Specialization not only allows you to hone your expertise but also positions you as a go-to authority in a particular domain.
Emerging Tech Pioneers: Technology never rests, and neither do SREs who wish to stay on the cutting edge. Specializing in emerging technologies like AI, machine learning, or blockchain can lead you to the forefront of innovation, where you’re crafting solutions that shape the tech landscape.
Industry Exploration: The SRE skill set is versatile and transferable. If you’ve mastered reliability in one industry, there’s no limit to where you can apply it. From finance to healthcare, e-commerce to entertainment – SREs can seamlessly transition across domains, bringing their expertise to diverse sectors.
Global Impact: The world is your playground. With tech being a global language, SREs can seek opportunities around the world. From Silicon Valley to international tech hubs, your expertise can make an impact on a global scale.
Entrepreneurial Ventures: Some SREs take their expertise a step further, venturing into entrepreneurship. Armed with a deep understanding of reliable systems, they create startups that leverage technology to solve real-world problems.
Lifelong Learning: Growth isn’t a destination; it’s a journey. SREs embrace continuous learning through online courses, workshops, conferences, and engaging with tech communities. This keeps them adaptable and ready to conquer new challenges.
Elevate Your SRE Journey: Whether you’re aiming for leadership, specialization, or global exploration, the SRE career path is a canvas for your aspirations. As technology evolves, your growth as an SRE is limitless, and each step forward adds another layer to your impressive tech tapestry.
External Link Suggestion: https://sre.google/sre-book/table-of-contents/
A Day in the Life of a Site Reliability Engineer: Navigating Challenges with Tech Prowess

As the sun rises on the digital landscape, Site Reliability Engineers (SREs) gear up for a day that’s as diverse as it is dynamic. From monitoring system health to resolving critical incidents, an SRE’s journey is a whirlwind of challenges and triumphs.
Challenge 1: System Health Monitoring The day kicks off with a vigilant eye on the system’s vitals. SREs dive into dashboards, analysing performance metrics to spot any anomalies or potential bottlenecks. They ensure that every component, from servers to databases, is functioning optimally, ready to tackle the day’s demands.
Solution: Automation tools are an SRE’s trusty sidekick. They set up alerts that ping them at the first sign of trouble. This proactive approach allows SREs to nip issues in the bud, preventing minor glitches from snowballing into major outages.
Challenge 2: Incident Response No tech landscape is without its hiccups. When an incident occurs, SREs spring into action. They identify the root cause, whether it’s a server overload or a network glitch, and collaborate with cross-functional teams to swiftly resolve the issue.
Solution: Post-mortems are a linchpin of the SRE strategy. Once the dust settles, SREs conduct detailed analyses of incidents, dissecting what went wrong and why. These insights drive continuous improvement, ensuring that history doesn’t repeat itself.
Challenge 3: Scalability Demands In a world where traffic spikes are a given, scalability is a must. SREs anticipate heavy loads, whether it’s during a product launch or a flash sale. They ensure that systems can gracefully handle surges without a hitch.
Solution: Autoscaling is the name of the game. SREs configure systems to expand or contract based on demand. This elasticity ensures that even during peak loads, users experience optimal performance without slowdowns.
Challenge 4: Balancing Reliability and Innovation The tech universe evolves rapidly, demanding innovation at every turn. However, SREs must strike a balance – innovate without compromising reliability. Deploying new features while ensuring no disruptions is an intricate dance.
Solution: Canary deployments are an SRE’s ace. They release updates to a subset of users, monitoring closely for any negative impacts. If issues arise, they can quickly roll back, ensuring minimal impact on the user base.
Challenge 5: Collaboration Across Teams SREs are bridge builders between development and operations teams. Effective communication and collaboration are essential to ensure that software is not just innovative but also robust.
Solution: Regular meetings and shared tools keep everyone on the same page. Chat platforms and documentation foster clear communication, ensuring that all teams work in sync towards common goals.
As the day winds down, the challenges of an SRE might ebb, but the quest for reliability never rests. Each challenge is a stepping stone towards mastering the art of maintaining seamless digital experiences.
External Link Suggestion: https://sre.google/sre-book/managing-incidents/
Conclusion
The role of a Site Reliability Engineer is akin to that of a guardian angel for the digital realm. They write code that sings in harmony with operations, keeping the wheels of technology spinning smoothly. As the architects of reliability, they design systems that can weather storms and surge ahead, ensuring that the heartbeat of modern tech never falters. In an age where downtime is a taboo and user expectations soar higher by the day, SREs stand as sentinels, embracing both the art of development and the science of operations in their unwavering pursuit of digital excellence.
FAQs
Sure, here are the top 10 most frequently asked questions on Google about Site Reliability Engineers (SREs) and their answers:
- What is a Site Reliability Engineer?
A Site Reliability Engineer (SRE) is a software engineer who works on the reliability, performance, and scalability of software systems. SREs use a combination of engineering practices, automation, and monitoring to prevent outages and ensure that systems are always available to users.
- What are the key responsibilities of a Site Reliability Engineer?
The key responsibilities of a Site Reliability Engineer include:
- Designing, building, and maintaining monitoring systems
- Automating tasks to improve efficiency
- Troubleshooting and resolving incidents
- Developing and implementing new reliability initiatives
- Working with other teams to improve the overall reliability of the system
- What are the skills and qualifications needed to be a Site Reliability Engineer?
The skills and qualifications needed to be a Site Reliability Engineer include:
- Strong understanding of software engineering principles
- Experience with monitoring and automation tools
- Ability to troubleshoot and resolve complex problems
- Excellent communication and teamwork skills
- Ability to work independently and as part of a team
- What is the difference between a Site Reliability Engineer and a DevOps engineer?
Site Reliability Engineers (SREs) and DevOps Engineers are both responsible for the reliability of software systems. However, there are some key differences between the two roles.
- SREs focus on the operational aspects of reliability, such as monitoring, alerting, and incident response.
- DevOps Engineers focus on the development aspects of reliability, such as continuous integration and continuous delivery (CI/CD).
In general, SREs are more technical than DevOps Engineers. They have a deeper understanding of the underlying systems and technologies. DevOps Engineers, on the other hand, have a broader understanding of the software development lifecycle.
- What is the future of Site Reliability Engineering?
The future of Site Reliability Engineering is bright. As software systems become more complex and critical, the demand for SREs will continue to grow. SREs are in high demand because they have the skills and experience to keep software systems running smoothly and reliably.
- What are some of the challenges faced by Site Reliability Engineers?
Some of the challenges faced by Site Reliability Engineers include:
- The increasing complexity of software systems
- The need to keep up with new technologies
- The pressure to meet ever-higher service level objectives (SLOs)
- The need to work with other teams, such as development and operations, to ensure the overall reliability of the system
- What are some of the benefits of being a Site Reliability Engineer?
Some of the benefits of being a Site Reliability Engineer include:
- The opportunity to work on challenging and interesting problems
- The chance to make a real impact on the reliability of critical systems
- The opportunity to learn new technologies and skills
- The potential for high salaries and job satisfaction
- What are the most important tools for Site Reliability Engineers?
The most important tools for Site Reliability Engineers include:
- Monitoring tools
- Automation tools
- Incident management tools
- Configuration management tools
- Logging and tracing tools
- What are some of the best practices for Site Reliability Engineers?
Some of the best practices for Site Reliability Engineers include:
- Designing for failure
- Automating everything
- Measuring everything
- Learning from failure
- Building relationships with other teams
- How can I become a Site Reliability Engineer?
There are many ways to become a Site Reliability Engineer. Some common paths include:
- Getting a degree in computer science or a related field
- Getting a certification in Site Reliability Engineering
- Getting experience in software engineering or DevOps
- Working as a Site Reliability Engineer intern



